Reinforcement Learning
원하는 작업의 달성을 위한 별도의 구체적인 지정없이 보상(Reward)과 벌칙 (Punishment)를 통한 Agent 학습
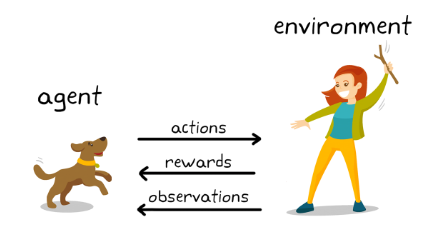
목표 : 축적된 보상을 최대화하는 control policy를 찾는 것
St : t시간의 State
At : t시간의 Action
St+1 : t+1시간의 State
Rt : Reward
S1 -> R1 -> A1 -> S2 -> R2 -> A2 -> S3 .. 지속반복하는 방법을 통하여 보상을 최대화하며 최적의 Policy를 찾아보는 것입니다.
위 그림에서 에이전트 (강아지)는 강화학습의 주체, 학습하는 대상이며, 각 상황(St)에서 Action을 하고 그에 따라 Environment (사람)는 보상(Reward)을 주고 다음 상태(St+1)의 정보를 제공합니다.
예를 들어) 강아지에게 막대기를 던져 잘 물고 돌아오면 간식 (양수의 Reward)을 주고, 물고 오지 않으면 간식을 주지 않는 (음수의 Reward) 것이라고 이해해 볼 수 있습니다.
MP (Markov Process, 마르코프 프로세스)
MP ≡ (State, Process)
MP (State, Process) → n개의 상태와 state transition function을 의미합니다

State S = {S0, S1, S2}으로 이루어져 총 3가지 State입니다.
Transition Function P : S → S, $P_{SS'} = P[S_{t+1} = s' | S_t = s]$
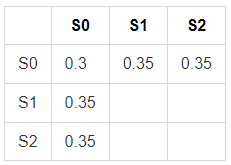
Markov Property : $P[ S_{t+1} | S_t ] = P [ S_{t+1} | S_1, S_2, S_3.. S_t ]$
→ "마르코프 성질"은 다음 State는 S1, S2.. 등 과거와 상관없이 현재 (St)에 의해서 결정된다는 것을 의미합니다.
즉, $S_{t+1}$ 가 될 확률을 계산하기 위해서 $S_1, S_2.. S_{t-1}$에 대한 정보는 t+1 시점에 아무런 의미가 없습니다.
MRP (Markov Reward Process, 마르코프 리워드 프로세스)
MRP ≡ (State, Process, Reward, gamma)
마르코프 프로세스 + Reward (보상) 개념이 추가된 프로세스입니다.

추가적으로 gamma (0 ≤ γ ≤ 1) 는 Discount factor입니다.
보상값에 γ을 곱하여, 미래의 보상을 얼마나 중요하게 여길 것인지를 나타내는 파라미터입니다.
Reward (보상)의 합을 리턴이라고 하며, $ Return = R_{t+1} + γ*R_{t+2} + γ^2*R_{t+3} + .. $ 처럼 나타낼 수 있습니다.
수식에서 알 수 있듯이 미래의 보상을 중요하게 생각한다면 γ = 0.9처럼 높은 값으로로 두어 더할 수 있습니다.
하지만, 미래의 보상을 중요하게 생각하지 않고 당장 현재의 보상만 탐욕적(Greedy)으로 본다면 γ = 0으로 두어 $ Return = R_{t+1} $으로 나타 낼 수 있습니다.
미래에 대한 보상은 불확실성을 반영합니다. 아무리 큰 보상이 미래에 있다고 하더라도 확률적인 요소로 인한 불확실성을 반영하기 위해서 gamma를 곱하여 더한다고 이해를 하면 될 것 같습니다.
맨 처음에서 말했듯이 강화학습은 축적된 보상을 최대화하는 control policy를 찾는 것으로,
다시 말하면 축적된 보상 (= 리턴)을 최대화 하도록 학습하는 것입니다.
MDP (Markov Decision Process, 마르코프 결정 프로세스)
MDP ≡ (State, Action, Process, Reward, gamma)
마르코프 리워드 프로세스 + Action (행동, 액션) 개념이 추가된 프로세스입니다.
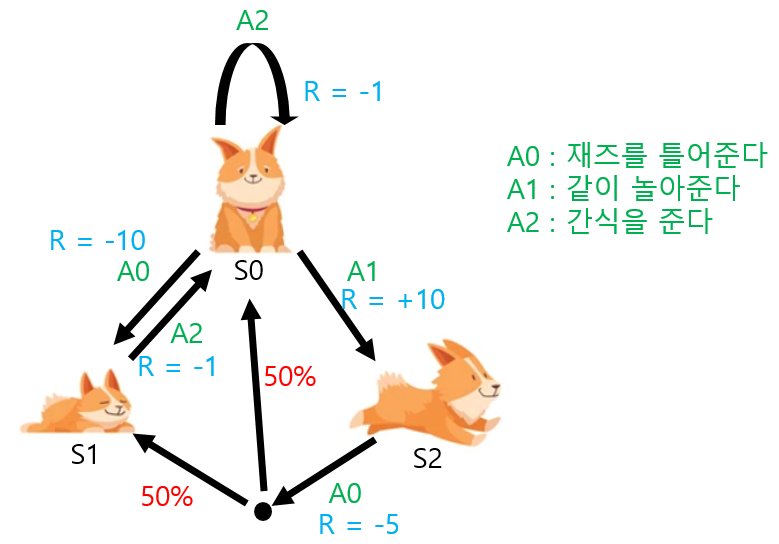
MP에서 알아보았던 전이확률도 Action이 추가되며 변했습니다.
$P^a_{SS'}$ → 현재 상태가 S일 때 다음 상태가 S'이 될 확률이라고 볼 수 있습니다.
※ 위 그림에서 S2 (강아지가 노는 상태)에서 A0의 action을 할 때, $P^{A_0}_{S2S0} = 0.5, P^{A_0}_{S2S1} = 0.5$ 입니다.
→ 액션을 선택했을 때 State가 변할 확률입니다. Action을 선택할 확률 ( = 정책 함수) 이 아닙니다.
여기에서 상태 S에서 특정 액션을 할때,
도달하게 되는 Next State S'은 1의 확률로 확실하게 결정되지 않는 다는 점이 존재합니다.
MDP에서는 조건부 확률을 통해 다음과 같이 나타낼 수 있습니다.
① Transition Function P : $P^A_{SS'} = P[S_{t+1} = s' | S_t = s, A_t = a]$
보상 R은 MDP에서는 액션이 추가되기 때문에 어떤 액션을 선택하냐에 따른 보상이 달라집니다.
즉, $R^a_s$은 State S에서 Action a를 할때의 보상값입니다.
E (기대값 ≒ 평균)을 이용해서 나타내는 것은 확률적으로 바뀌기 때문입니다.
② Reward : $ R^a_s = E [R_{t+1} | S_t = s, A_t = a ] $
Agent의 3가지 Components [Policy / Value Function / Model]
1) Policy
정책은 각 상태에서 Agent가 어떤 행동(=액션)을 할지 정하는 함수입니다.
π(a∣s)=P[At=a∣St=s]
상태 S에서 액션 a를 선택할 확률
S0에서 어떤 액션(A1 or A2)을 통하여 S1 혹은 S2로 갈수 있다고 가정할때
다음과 같이 정책함수를 결정해볼 수 있습니다.
π(a1∣s=S0) = 0.5
π(a2∣s=S0) = 0.5
이 때 모든 Action의 확률값의 합은 1입니다.
정책함수는 State에서 각 액션을 선택할 확률입니다.
MDP에서 본 내용은, 액션을 선택했을 때 State가 변할 확률입니다. (헷갈리지 말 것)
정책 (Policy)은 $\pi$를 이용하여 나타냅니다.
여기에서, 정책은 액션을 선택할 확률이라고 하였습니다. 즉, 보상값이 최대가 되도록 액션을 선택할 확률을 변경해나가는 것이 강화학습이라고 입니다.
2) Value Function
MDP에서의 Value Function은 1) State Value Function 2) Action Value Function 2가지로 나눌 수 있습니다.
① State Value Function
$V_{\pi}(s)$ 각 정책함수에 따른 리턴 (축적된 보상의 합)의 기댓값입니다.
$V_{\pi}(s) $ = $ E_{\pi}$$[ Return_t | S_t = s ] $
$ Return = R_{t+1} + γ*R_{t+2} + γ^2*R_{t+3} + .. $
② Action Value Function
State Value Function은 특정정책함수 ${\pi}$ 에서 state에서의 리턴값의 기대값을 통해서 state을 평가한 것입니다.
Action Value Function은 ${\pi}$에서 state에서의 액션을 평가하겠다는 내용입니다.
State s0에서 모든 액션을 평가하여 가장 가치있는 액션을 선택할 수 있게 됩니다.
$Q_{\pi}(s, a) $ = $ E_{\pi}$$[Return_t | S_t = s, At = a ] $
특정 상태에서 액션을 평가하기 위해서, state와 액션을 넣어 리턴의 기댓값을 액션 가치 함수라고 합니다.
이 수식을 통하여, S에서 a를 선택하는 것에 대한 가치를 알 수 있습니다.
상태 가치 함수 => 상태 s일 때 가치 => 정책함수가 action을 고른다.
액션 가치 함수 => 상태 s, 액션 a를 했을 때의 가치 => action a를 강제로 고른다.
3) Model : agent가 가지는 환경 모델
Prediction / Control
1. Prediction : 정책함수 ($\pi$)를 알고 있을 때 각 state의 value를 평가함 (미래를 평가)
- Under (Given a policy function)
- Find the value function
2. Control
- 최적의 Policy ($\pi^*$)를 찾는 것 (알파고의 경우, 어떤상대를 만나도 이기는 바둑을 이기는 정책)
- 최적의 Policy $\pi^*$ 를 찾았을 때, Optimal 가치함수($\V^*$)를 찾으면 MDP를 풀 수 있습니다.
'스터디 공간' 카테고리의 다른 글
| [Python-Leetcode] 509. Fibonacci Number (difficulty : Easy - ☆) (0) | 2022.05.06 |
|---|---|
| [강화학습][2] Reinforcement Learning (0) | 2022.05.05 |
| [Python-Leetcode] 13. Roman to Integer (difficulty : Easy - ☆) (0) | 2022.05.05 |
| [Python-Leetcode] 1. Two Sum (difficulty : Easy - ☆) (0) | 2022.05.01 |
| [Python-Leetcode] 2. Add Two Numbers (difficulty : Medium - ☆☆) (0) | 2022.04.30 |




댓글