◆ Numpy 기초 스터디
- numpy = numerical python / 파이썬 데이터 과학의 핵심 라이브러리
- import numpy as np
◆ Numpy Basic Concept
python의 데이터를 담는 기본적인 컨테이너는 list(리스트) 입니다. python은 동적 타이핑(dynamic typing)을 지원하기 때문에, 각각 서로 다른 데이터의 형식을 담는 리스트를 생성 할 수 있습니다. 파이썬은 이처럼 유연한 타입을 허용하기 때문에, 리스트의 각 항목에 타입의 정보 등을 가지고 있어야 하며, 이는 때때로 고정 타입 배열 형식에 비해서 비효율적으로 보일 수 있습니다. 리스트는 굉장히 유연한 것이 장점이지만, 때때로 비효율적일 수 있습니다.

그런 리스트와 달리, 효율적으로 고정 타입 배열을 사용하는 것이 바로 'numpy'라고 볼 수 있습니다. numpy는 기본적으로 array 안의 데이터는 같은 데이터를 넣어주어야하며, 타입이 일치하지 않을 경우 다른 타입으로 일괄적으로 변경시키게 됩니다.
아래의 test2의 '5'는 str 같지만, float로 변경하여 저장을 시키게 되는 것을 볼 수 있습니다.
[IN]

[Out]

◆ Numpy 배열 생성
- np.zeros : 0의 배열 생성
- np.ones : 1의 배열 생성
- np.eye(n) : n x n 매트릭스형태의배열 생성
[IN]

[OUT]
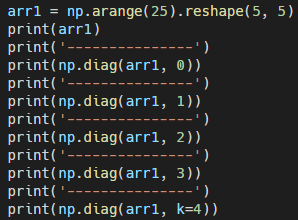
- np.diag(배열, k=number)
배열의 대각선으로 값을 가져온다. 대각선 info를 가져올 때 유용하게 쓸 수 있을 듯하다.
일반적으로 저는 s-parameter값을 z-parameter로 변환하여, self-impedance로 변환하기 위해서 데이터를 가져올 때 유용하게 사용했었습니다. (예)
[IN]
[OUT]

- np.random.normal(0, 1, size) : 평균이 0, 표준편차가 1인 정규 분포 생성 - np.random.randint(low_num, high_num, size) : low_number~high_number사이의 숫자 생성
- np.random.uniform(low_num, high_num, size)
다음의 그래프를 보고 이해해봅시다. normal은 정규분포의 형태를 띈다는 것을 확인할 수 있으며, uniform은, 각 데이터의 분포가 균등하게 나온다는 것을 확인할 수 있습니다.
|
[IN]  [OUT]  |
◆ Numpy 데이터 타입
- 데이터타입은 array / arange 등을 사용할 때 타입을 지정해 줄 수 있습니다.
- np.array([1, 2, 3], dtype='int8')
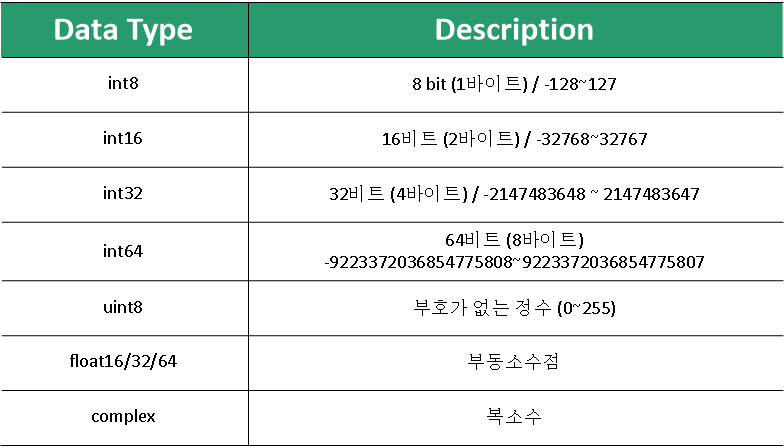
- 이 중 uint는 부호가 없습니다. 그래서 -127을 uint8 (8비트)의 데이터 타입으로 지정하여 print를 해주면, 129가 나오는 것을 확인 할 수 있습니다. 이는 int에서는 127을 binary로 표현해보면 '0111 1111'에서 맨 처음 0을 +부호 인덱스로 보기 때문에 이의 보수인 1000 0001을 -127로 표현한다는 것을 알 수 있습니다. 즉, -127의 bin값은 '1000 0001' 이나, uint에서는 맨 처음 비트를 부호 비트로 보지 않기 때문에 129로 표현된다는 것을 확인할 수 있습니다.
[IN]

[OUT]

'스터디 공간' 카테고리의 다른 글
| [Python-Study Leetcode 문제풀이] 121. Best Time to Buy and Sell Stock (Easy) (0) | 2021.03.14 |
|---|---|
| [Python Study] VS Code vs. Juputer Notebook (0) | 2021.03.14 |
| [PYTHON study - Seaborn] Graph plot (1) (0) | 2021.03.04 |
| [회로이론] 인덕터 (Inductor) (0) | 2021.03.01 |
| [회로이론] Spectre (2) - Syntax (0) | 2021.03.01 |




댓글