■ python study seaborn(씨봄/세아봄)
파이썬 데이터 처리를 하기 위해서는 통계적인 지식이나, 파이썬 스킬도 중요하지만,
파이썬의 강력한 기능 중 하나인 시각화 도구를 잘 다루는 것도 중요합니다.
일반적으로 주로 사용하는 matplotlib와 seaborn이 있으며, 그 중 세련된 시각화 이미지를 제공해주는 seaborn을 알아보겠습니다.

▷ Basic plot (가장 기본적으로 사용되는 7가지 정도의 plot)
- lineplot
- countplot
- scatterplot
- barplot
- (분포 특성) kdeplot, distplot, heatmap
1. lineplot


sns.lineplot(x='x축에 넣을 데이터', y='y축에 넣을 데이터', data='불러올 데이터')의 형태로 사용할 수 있습니다.
|
[In]  |
|
[Out]  |
추가적으로 hue를 넣어서, 다음과 같이 데이터를 분리하여 보여 줄 수 있습니다.
|
[In]  |
|
[Out] 
|
2. countplot
① countplot은, 데이터의 개수를 세서 y축에 보여주는 역할을 합니다.
담배를 피는 사람의 성별(hue='sex')에 따라서 count를 한 결과는 아래와 같습니다.
② hue_order=['Female', 'Male']을 하게되면, 그래프의 순서를 바꿔줍니다.
|
[In]  |
|
[Out]  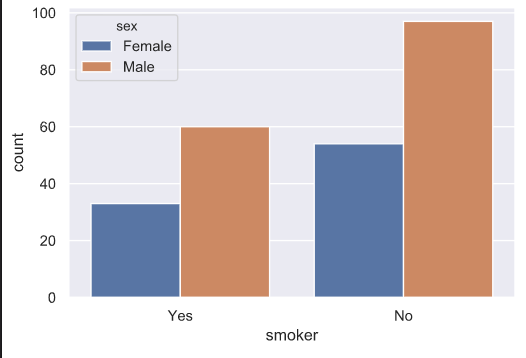 (hue_order=['Female', 'Male']) |
3. scatterplot
방금 전 확인한 데이터를 scatterplot으로 확인해보면, 점의 모양으로 분포를 확인할 수 있습니다.
값의 분포를 확인할 때 유용하게 사용할 수 있습니다.
|
[In]  |
|
[Out] 
|
scatter plot을 이용하여, total_bill과 tip의 상관관계를 살펴보겠습니다
total_bill이 증가할수록 tip도 증가하는 모습을 가진 것을 알 수 있습니다.
이렇게 scatterplot을 이용하여 직관적으로 데이터의 모양을 이해할 수 있습니다.
|
[In]  |
|
[Out]  |
4. barplot
barplot은 해당 데이터에 대한 평균치를 보여줍니다.
tips 데이터에서 날짜별 tip의 평균을 보고 싶을 경우에 sns.barplot(x='day', y='tip', data=tips) 처럼 입력할 수 있습니다.
각 평균치가 맞는지는 df의 groupby를 사용하여 확인해보도록 하겠습니다.
tips.groupby('day')['tips'] 는, tips 데이터의 'day' 컬럼으로 한번 필터링을 거치고, tips 컬럼에 대한 값을 뽑아낸 것이라고 이해를 하면 될 거 같습니다. 그리고, 그 값에 대한 평균값(mean())을 통해서, 값을 확인 할 수 있으며 그 값은 각 막대 그래프와 일치한다는 것을 확인할 수 있습니다.
|
[In]  |
|
[Out] 
 |
5. distplot
distplot은 값의 분포를 확인할 수 있습니다. hist(히스토그램)와 비슷하다고 이해볼 수 있습니다.
tips의 값의 분포를 살펴보겠습니다. 값을 확인해보면, 2~4에 대한 값의 분포가 대부분이라는 것을 살펴볼 수 있습니다.
bins는 막대 그래프의 개수입니다.
|
[In]  |
|
[Out] 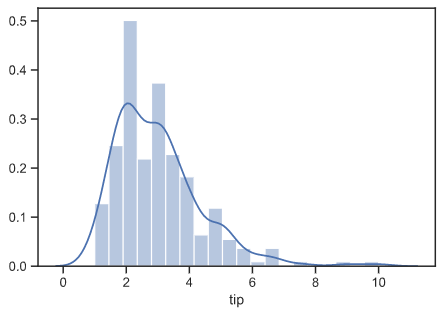 |
6. heatmap
heatmap 역시, 값의 분포를 확인할 수 있습니다. 단, heatmap 매트릭스의 형태로 넣어주어야 합니다.
titanic 데이터를 가지고 heatmap을 한번 살펴보도록 하겠습니다.
① load_dataset('titanic')을 통해서 데이터를 가지고 오도록 합니다.
② df.corr()은 상관관계의 형태로 데이터를 보여주며 해당 상관관계는 매트릭스의 형태를 가집니다.
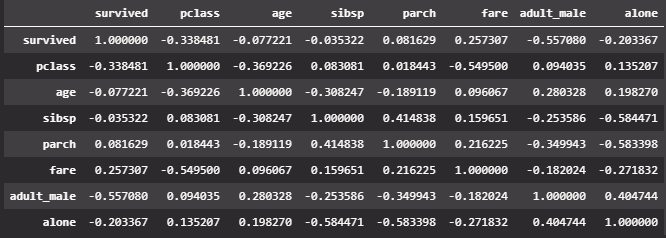
③ sns.heatmap을 통해서, 데이터를 시각화해보겠습니다.
아래와 같이 그림의 색을 통해서, 매트릭스 형태의 데이터로 확인할 수 있습니다.
(+ 우측의 색 속성은, vmin=-1, vmax=1의 파라미터를 통해서 설정이 가능합니다.)
|
[In]  |
|
[Out] 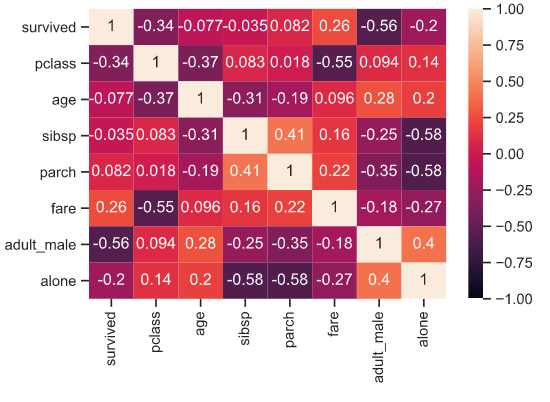 |
타이타닉을 탑승한 승객 중, 성별과 survived의 관계를 살펴보겠습니다.
해당 데이터처럼, 여성 분들이 +의 상관관계를 가지는 것으로 보아 남성들보다 여성들이 더 많이 살아 남은 것을 보여줍니다.
|
[In] 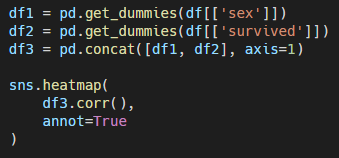 |
|
[Out] 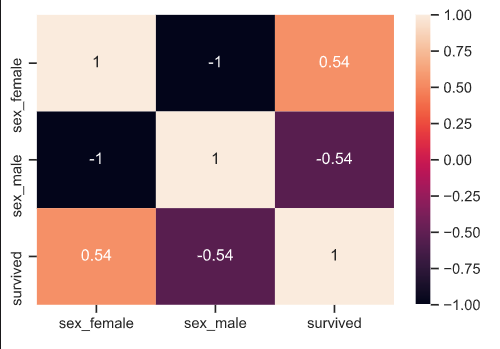 |
7. kdeplot
분포를 보여주는 kdeplot은 1차원 데이터, 2차원데이터를 보여주는 기능을 합니다.
아래와 같이 kdeplot(데이터)를 쓰게되면, 1차원의 데이터 분포를 보여줍니다.
|
[In]  |
|
[Out] 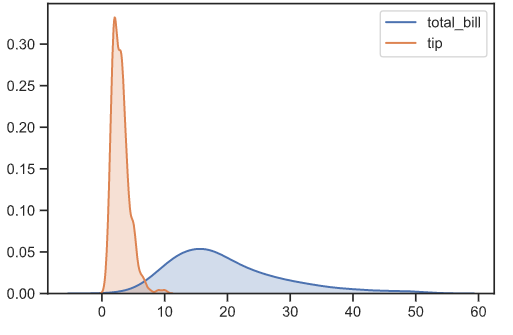
|
2차원 데이터의 분포를 보려면, sns.kdeplot(데이터1, 데이터2)의 format으로 적을 시, 해당 데이터의 분포를 2차원 형태로 볼 수 있게됩니다.
shade_lowest는 가장 낮은 테두리를 벗어나게 되면, 투명하게 해주는 옵션입니다.
shade_lowest가 없으면, axes 전체가 파란색이 되니, 사용해주면 좋을 것 같습니다.
|
[In]  |
|
[Out] 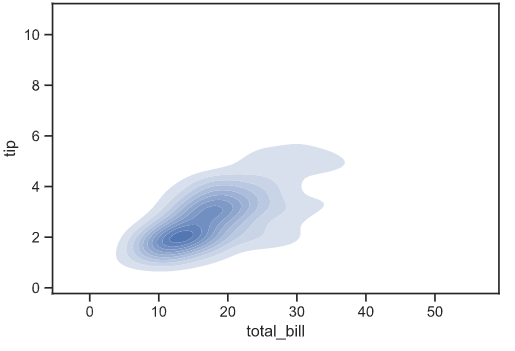 |
'스터디 공간' 카테고리의 다른 글
| [Python Study] VS Code vs. Juputer Notebook (0) | 2021.03.14 |
|---|---|
| [데이터 분석] numpy (1) (0) | 2021.03.06 |
| [회로이론] 인덕터 (Inductor) (0) | 2021.03.01 |
| [회로이론] Spectre (2) - Syntax (0) | 2021.03.01 |
| [Pandas] 누락 데이터 처리 (0) | 2021.03.01 |




댓글